Investigating a Local Minimum
I've been training an AlphaZero-style agent to learn, on its own, how to play a form of turn-based TETR.IO, a kind of competitive two-player Tetris. After a while, however, progress stagnated. I used some statistics to track skill level, and they eventually flattened out. Additionally, the agent's win rate against previous checkpoints stopped moving.
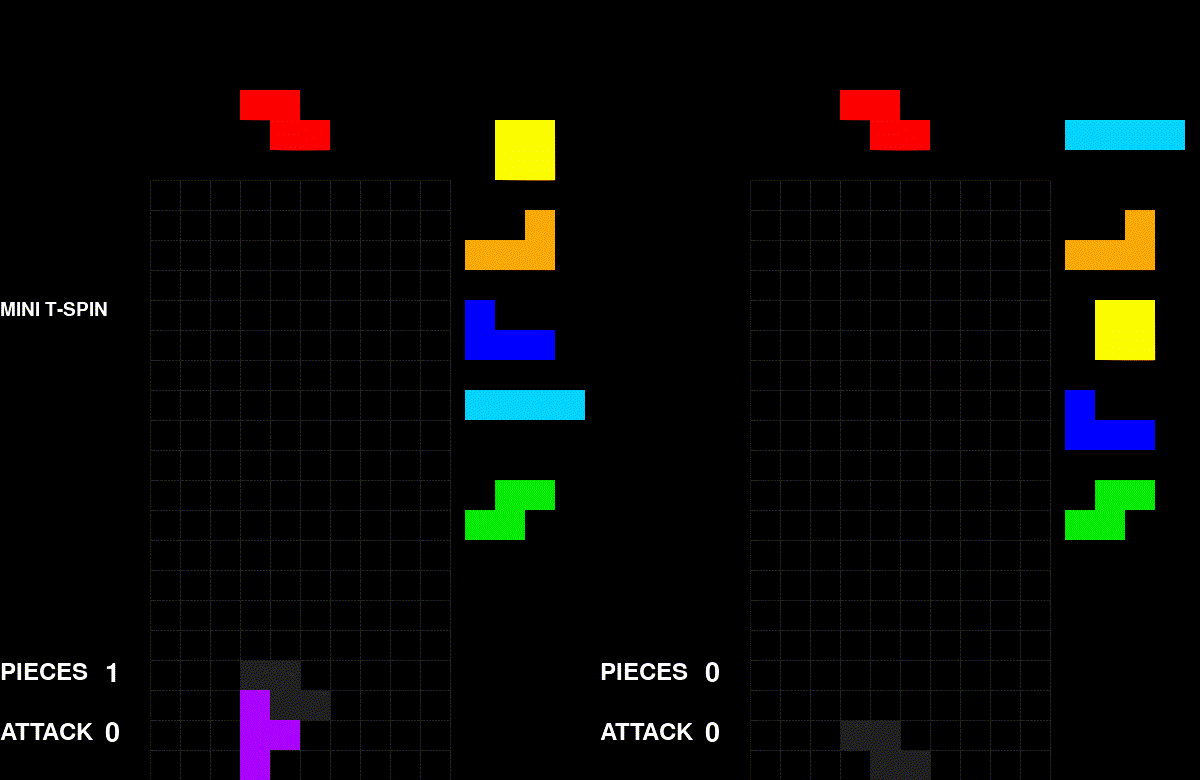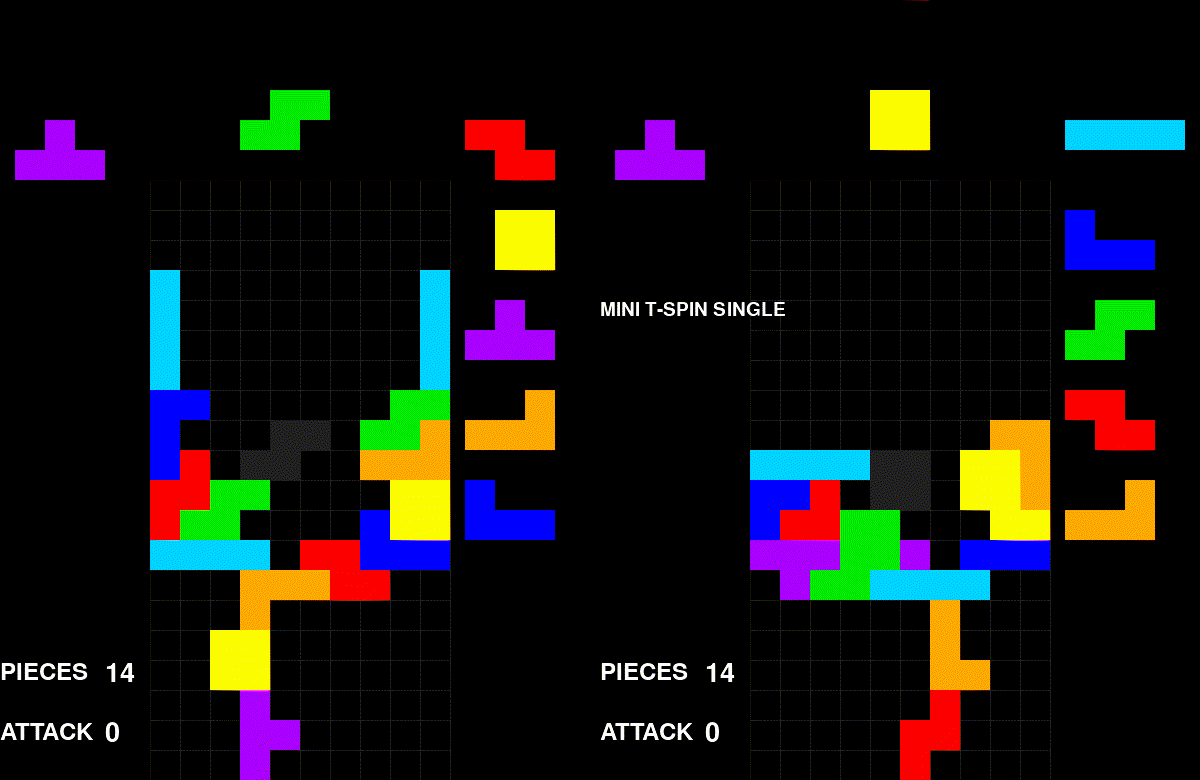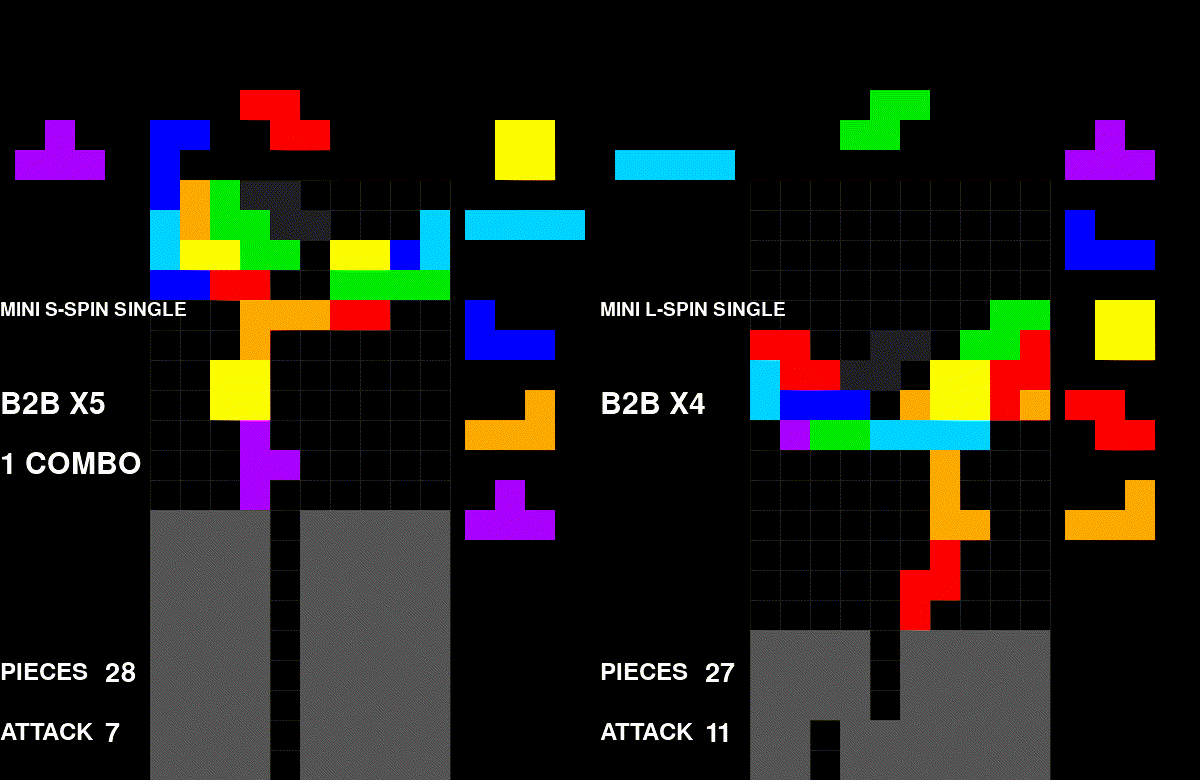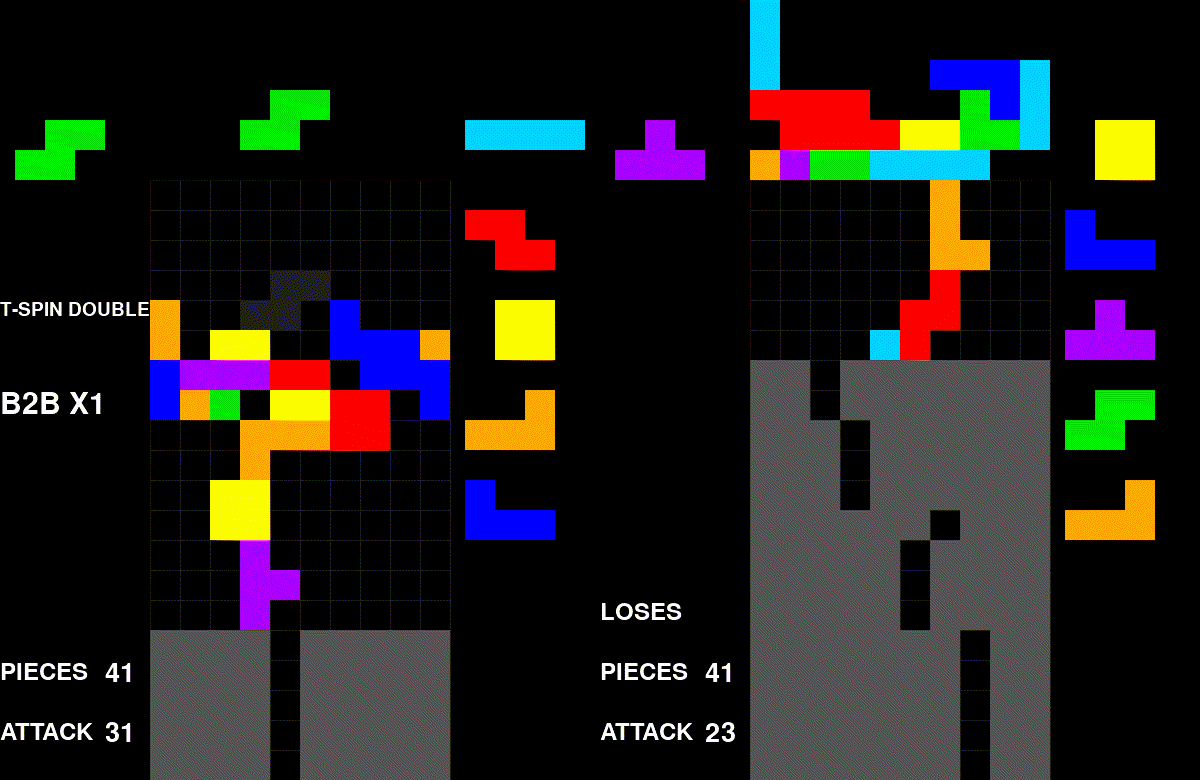
A self-play game of my algorithm. Every game looks similar to this.
Visually, the problem is quite obvious. The agent converged on one style: stack aggressively, send garbage, repeat. This post is my attempt to uncover why it converged on this specific strategy.
Chapter 1.
1. Is exploration the problem?
AlphaZero uses Dirichlet noise to force the search to consider moves it might otherwise ignore. A parameter α controls how aggressive that noise is — too small and the search barely deviates from its policy, too large and it becomes essentially random.
I ran 10 games and at each position compared the search's move choice with and without noise across a sweep of α values, tracking three things: how often the move changed, how broadly visits were spread, and how concentrated they were on the top move.
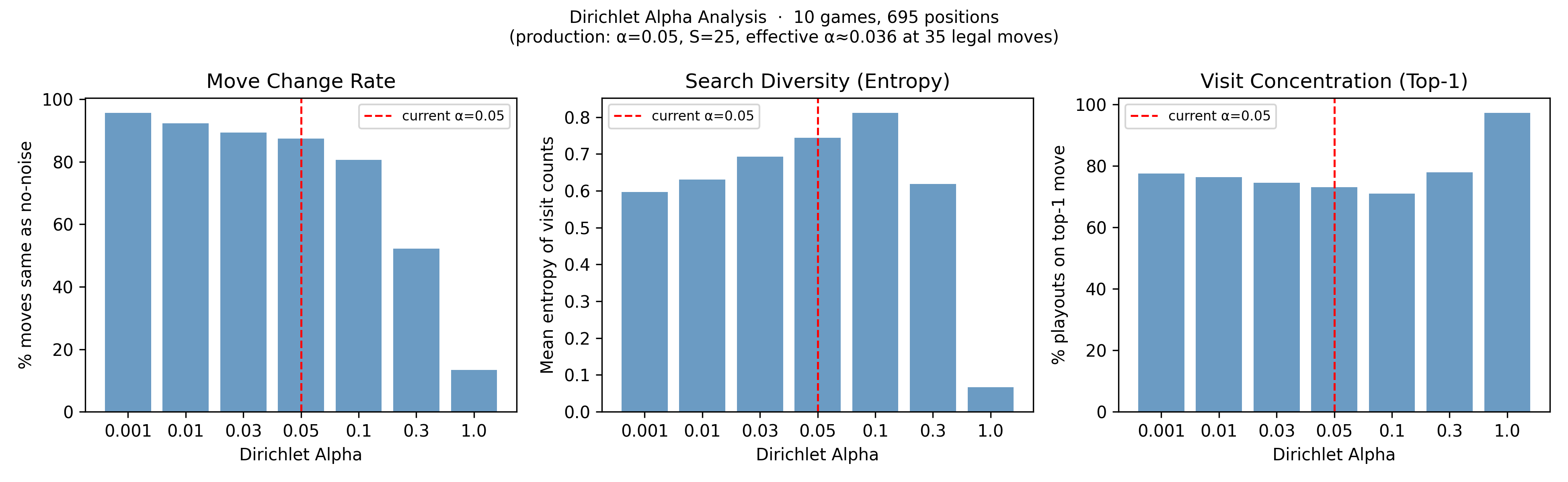
The three panels tell the same story from different angles. At my production setting of α = 0.05 (marked with a red dashed line), the noise is at a solid level of increasing search diversity without overly changing chosen moves. The graphs also show that α = 0.001 barely affects the chosen move, while α > 0.3 makes the search chaotic.
These show that exploration is working as intended. I changed α: 0.05 -> 0.1 so as to increase the search diversity. However, these graphs are evidence that is this is not the cause of the local minima.
2. What is MCTS actually doing?
Given that the dirichlet alpha was fine, my next focus was the Monte Carlo Tree Search, the tree search algorithm which uses the neural network's policy and value outputs to guide tree expansion to simulate game playouts. Across 5 games I collected nine relevant metrics:
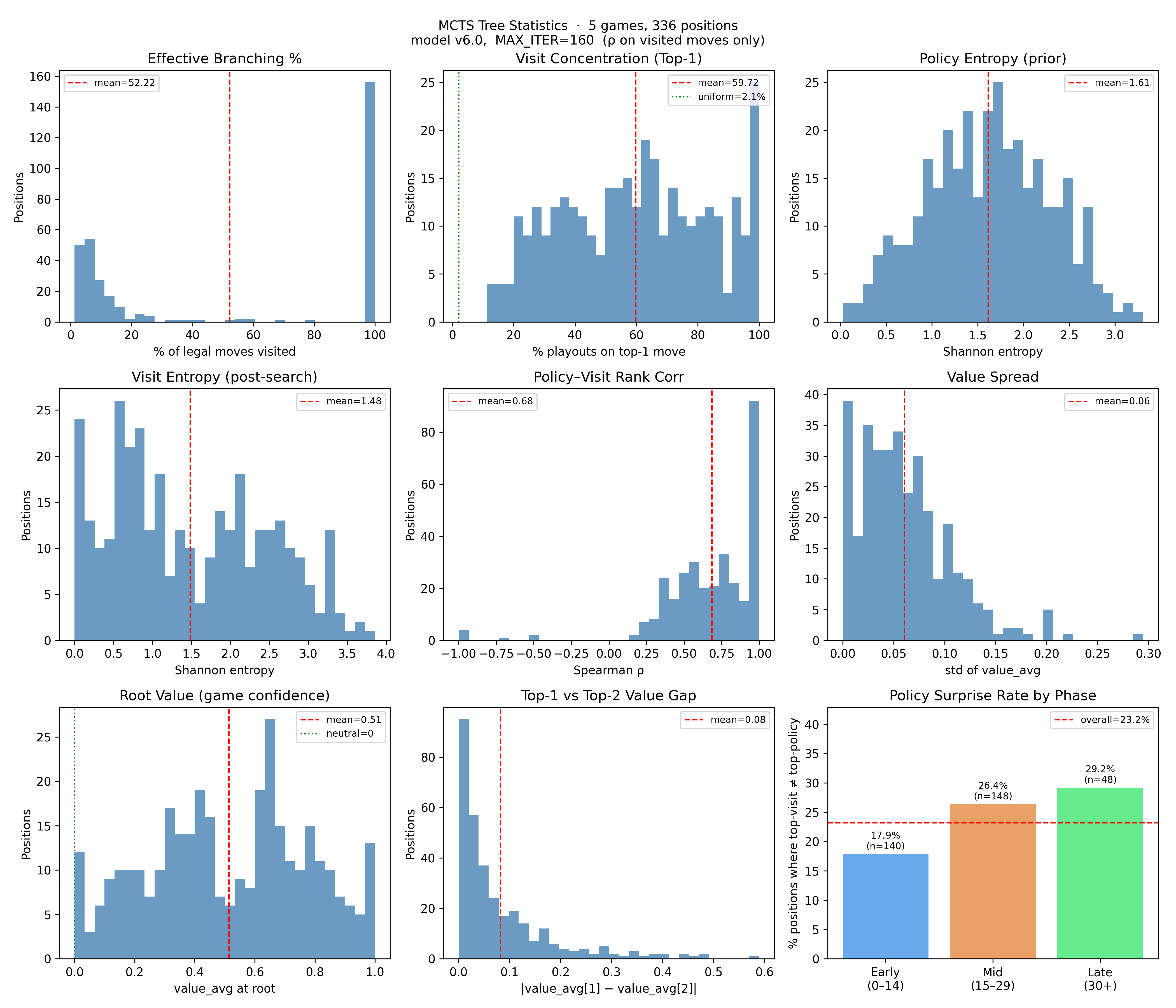
Effective Branching % (mean 52%) represents the percentage of child nodes of root node that were looked at. Notably, the distribution is bimodal. Most positions either have visits spread across nearly every legal move, or almost entirely collapsed onto one. There's not much in between.
Visit Concentration (Top-1) shows the percentage of playouts given to the highest looked at node. (mean 59.7%) This confirms the collapse side of that picture. On average, one move gets 60% of the search budget — and many positions have all 160 playouts going to a single move. For context, the green dotted line shows what uniform allocation would look like (~2%). The agent is nowhere near that.
Policy entropy (the network's raw output) averages 1.61. Visit entropy (post-search) is 1.48. The search is making the distribution narrower, as expected.
Policy-Visit Rank Corr (mean 0.68) measures the Spearman rank correlation between the policy prior and the final visit distribution. A value of 1.0 would mean the search spent playouts in exactly the order the network predicted. At 0.68, the search mostly follows the policy's ranking — but diverges meaningfully in a number of positions, consistent with the 23% policy surprise rate.
Value panels show that the average value spread across visited moves is 0.06 on a [0,1] scale, and the average gap between the top two moves is only 0.08, corresponding to 6 percentage points and 8 percentage points respectively.
Policy surprise rate (23% overall, rising from 18% early game to 29% late) shows that search is changing the decision about 1 in 4 times.
Is the value head broken?
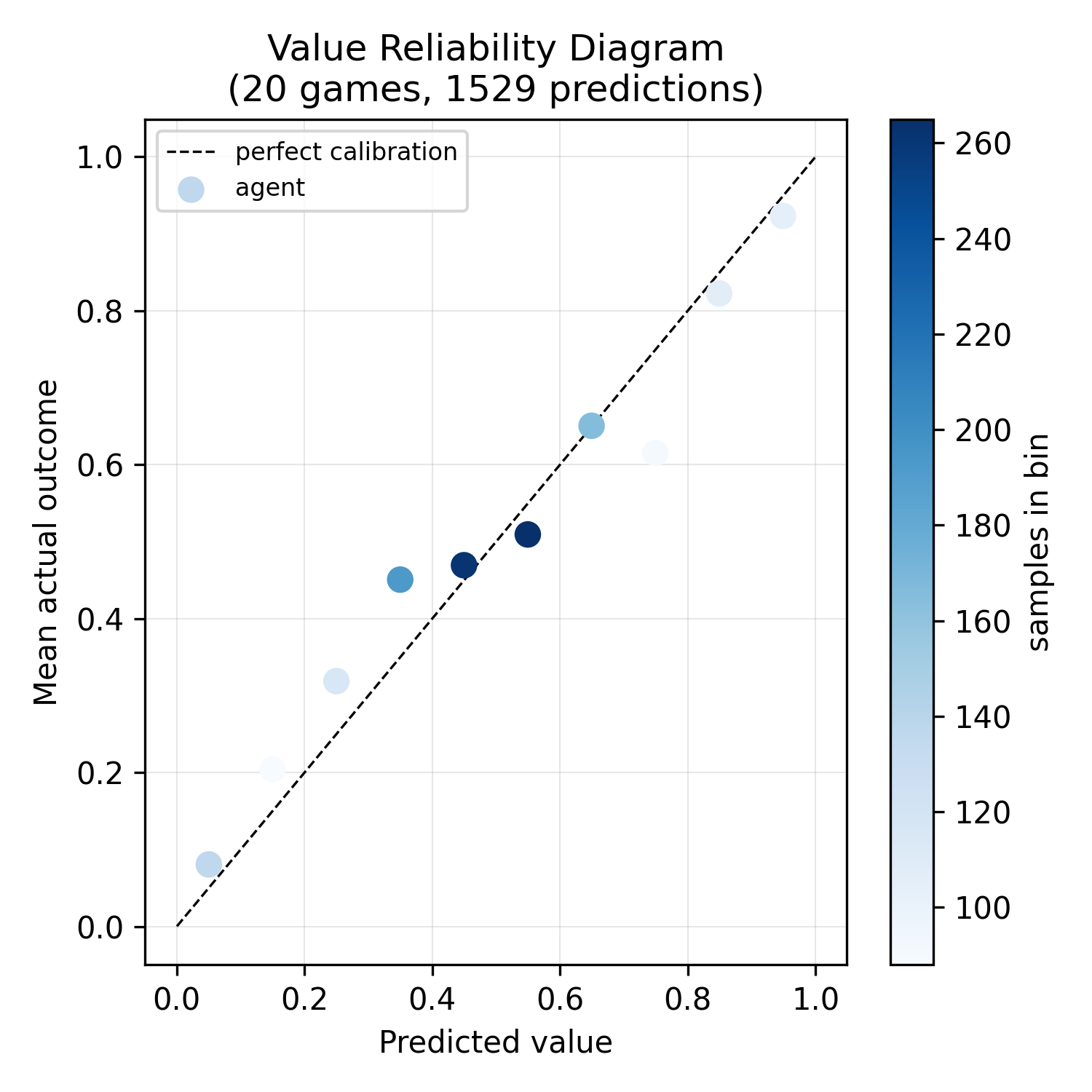
Short answer: no. This reliability diagram shows the network's predicted win probability against actual outcomes, bucketed. Points on the diagonal mean perfect calibration. The agent tracks the diagonal reasonably well.
However, the graph shows that the majority of positions are being evaluated as near coin-flips. The value head is uncertain, meaning the tree search has a more difficult time discerning which lines are actually promising beyond the policy prior. This could lead to a cycle where the agent is dominated by the policy during self-play games, leading to narrow training data, confining the network to that style. This is a potential cause of the local minima.
Does more compute help?
Running the same analysis at 800 iterations (5× the default) to see what difference more compute makes.
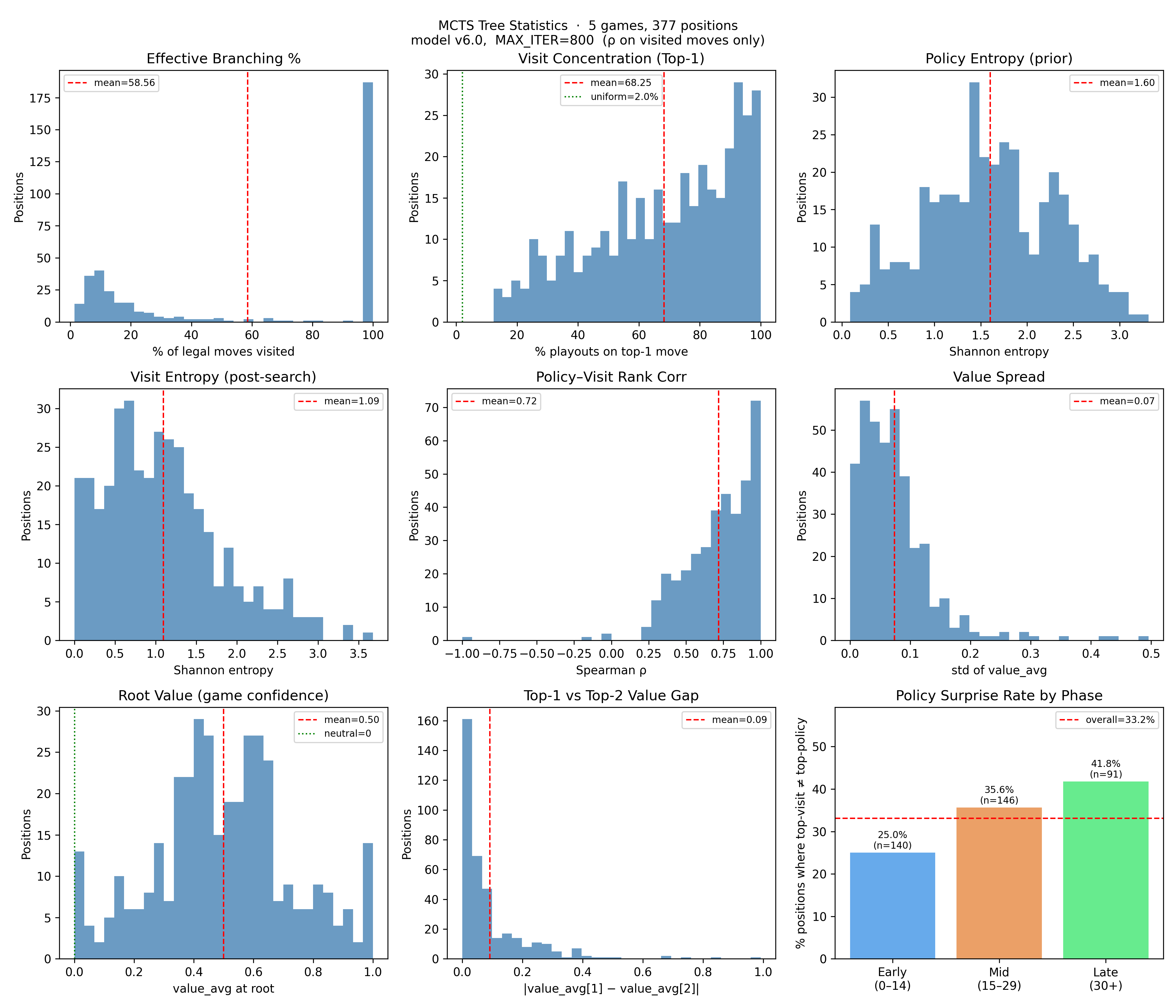
| Metric | 160 iter | 800 iter |
|---|---|---|
| Effective Branching % | 52.2% | 58.6% |
| Visit Concentration (Top-1) | 59.7% | 68.3% |
| Visit Entropy | 1.48 | 1.09 |
| Value Spread | 0.06 | 0.07 |
| Policy Surprise Rate | 23.2% | 33.2% |
The value spread barely moves. More playouts don't change what the network knows — they just let PUCT compound harder on whatever move pulled ahead first, which is why concentration increases. Policy surprise increases as expected, which means more iterations genuinely push the search to deviate from the prior more often (especially late game, where it jumps to 42%).
More compute here would help, but it doesn't look like it will solve the problem.
3. Is the training configuration making it worse?
My agent uses a self-learning idea from KataGo — Forced Playouts and Policy Target Pruning: Children of the root node are forcibly visited based on the policy and total playouts. Also, to prevent training from being influenced by bad "forced" moves, the algorithm prunes nodes that would not normally have been chosen.
The CForcedPlayout parameter determines how strong this is; a higher value means more forced playouts and more pruning. My algorithm uses a default value of 1.
Additionally, some features are turned on or off depending on whether the agent's mode is training or evaluation. The evaluation mode doesn't use the following:
- Forced playouts and policy target pruning
- Dirichlet alpha
- Temperature (which adds randomness to move selection, affecting the behavioral policy)
- Randomized playouts (which randomizes the number of MCTS)
To examine these, I compared these four configurations on identical positions:
- Eval: standard evaluation mode
- Train standard training mode
- Train+CForced=3: training mode with CForcedPlayout=3
- Train-Forced standard training mode without forced playouts
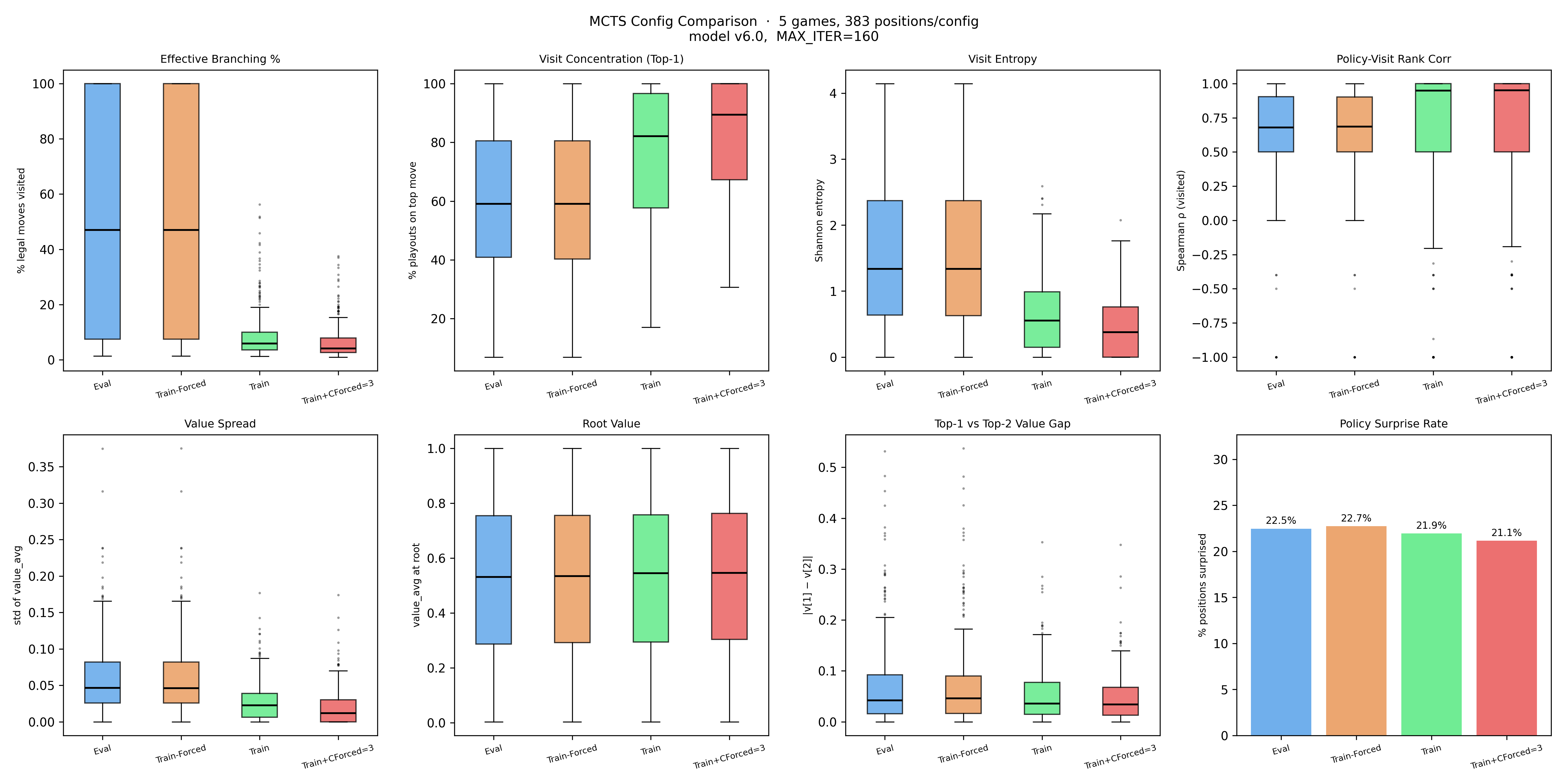
Comparing Train vs Train-Forced makes it clear: the policy target pruning that runs after move selection, deliberately zeroing out low-value visits before they become training labels is what's reducing the branching %. That is what policy target pruning is meant to do; it sharpens the policy target. More aggressive pruning (CForced=3) heightens the disparity.
Because the value head is already uncertain and possibly be causing the local minima, these findings support that turning off Forced Playouts will help the agent distinguish between different states.
4. Has the network actually been learning?
The search diagnostics show that something is wrong, but they're taken from a single snapshot. The training loss curves provide more information about how well the algorithm is performing.
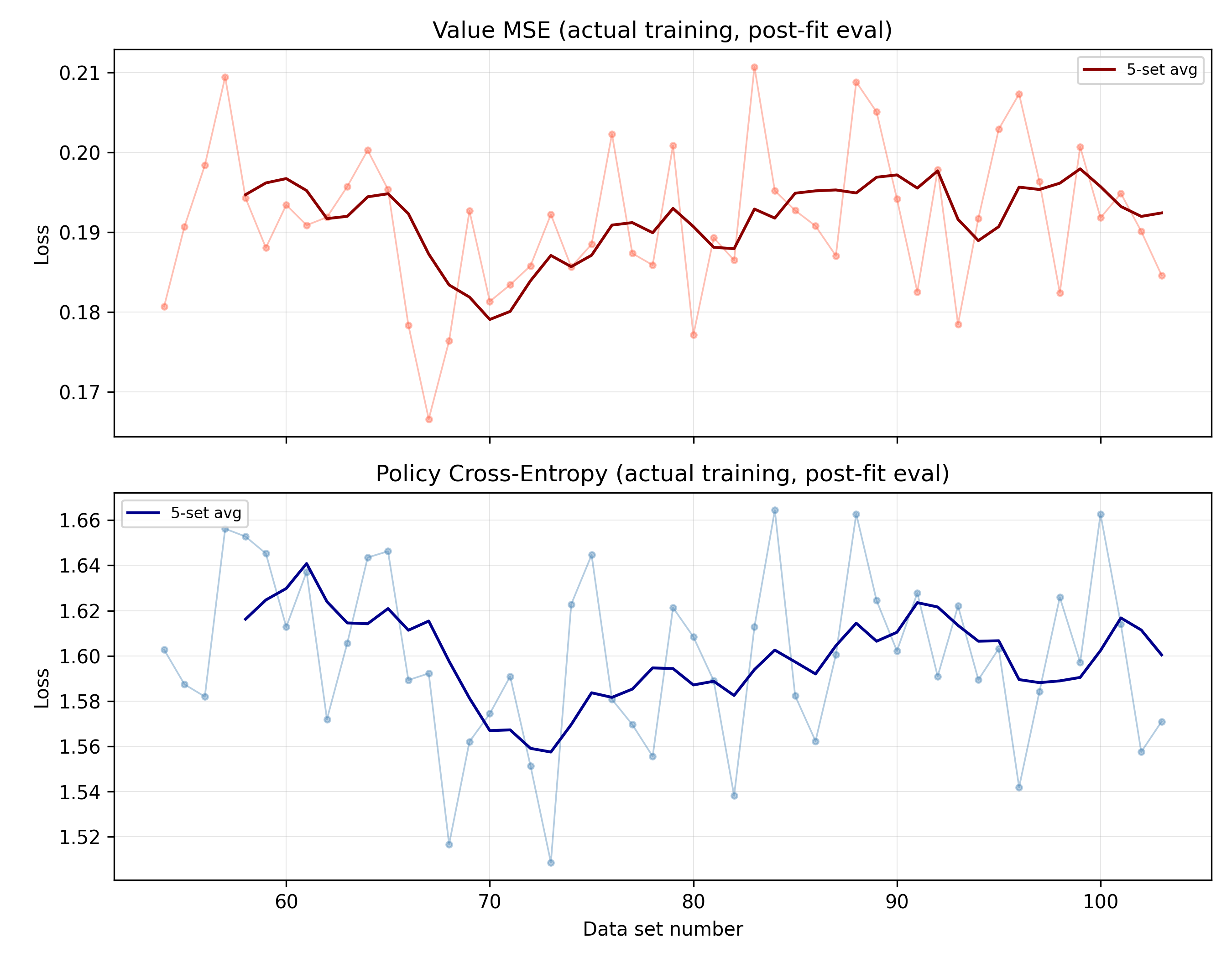
Both heads have flatlined. Value MSE has hovered between 0.18 and 0.20 for the last 50 datasets, with a brief dip to ~0.18 around dataset that didn't hold. Policy cross-entropy shows the same pattern — the 5-set smoothed average sits around 1.56–1.64.
The loss curves do not directly measure playing strength; they measure how well the network fits the self-play targets it is given. So the flat policy and value losses do not prove the model has stopped getting stronger. What they do show is that, for roughly the last 50 datasets, the network is fitting its targets to about the same degree as before.
There's a second chart that adds a wrinkle to that picture.
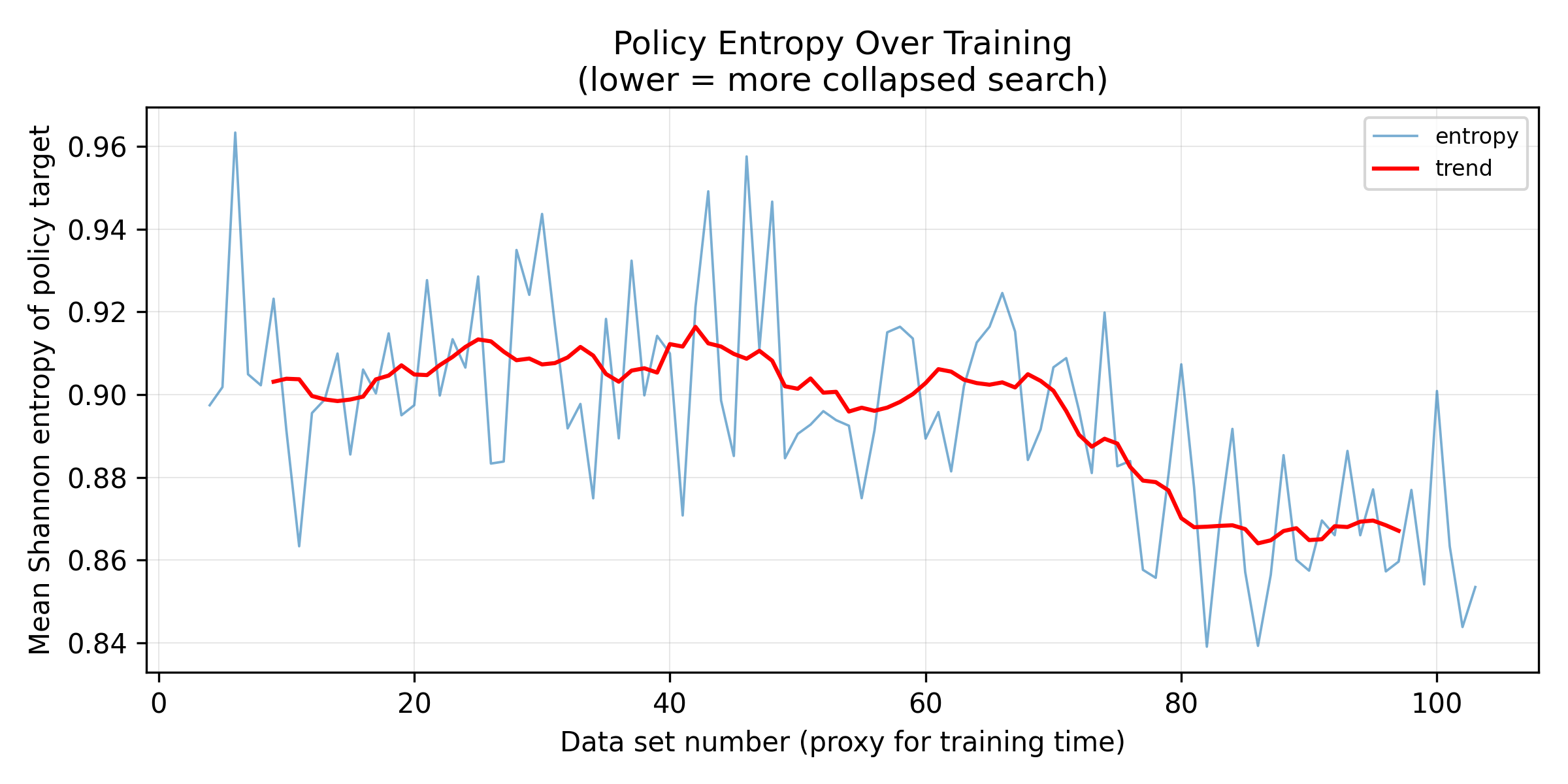
This tracks the mean Shannon entropy of the policy targets generated during self-play — a direct measure of how concentrated the search's move distributions are becoming. From datasets 0–80 the trend is flat around 0.91. After that it drops steadily to ~0.87 by dataset 100.
This means the search is producing increasingly concentrated move distributions. Combined with the earlier search diagnostics, this suggests that the self-play targets may be getting narrower without becoming more informative.
5. Analyzing compute more
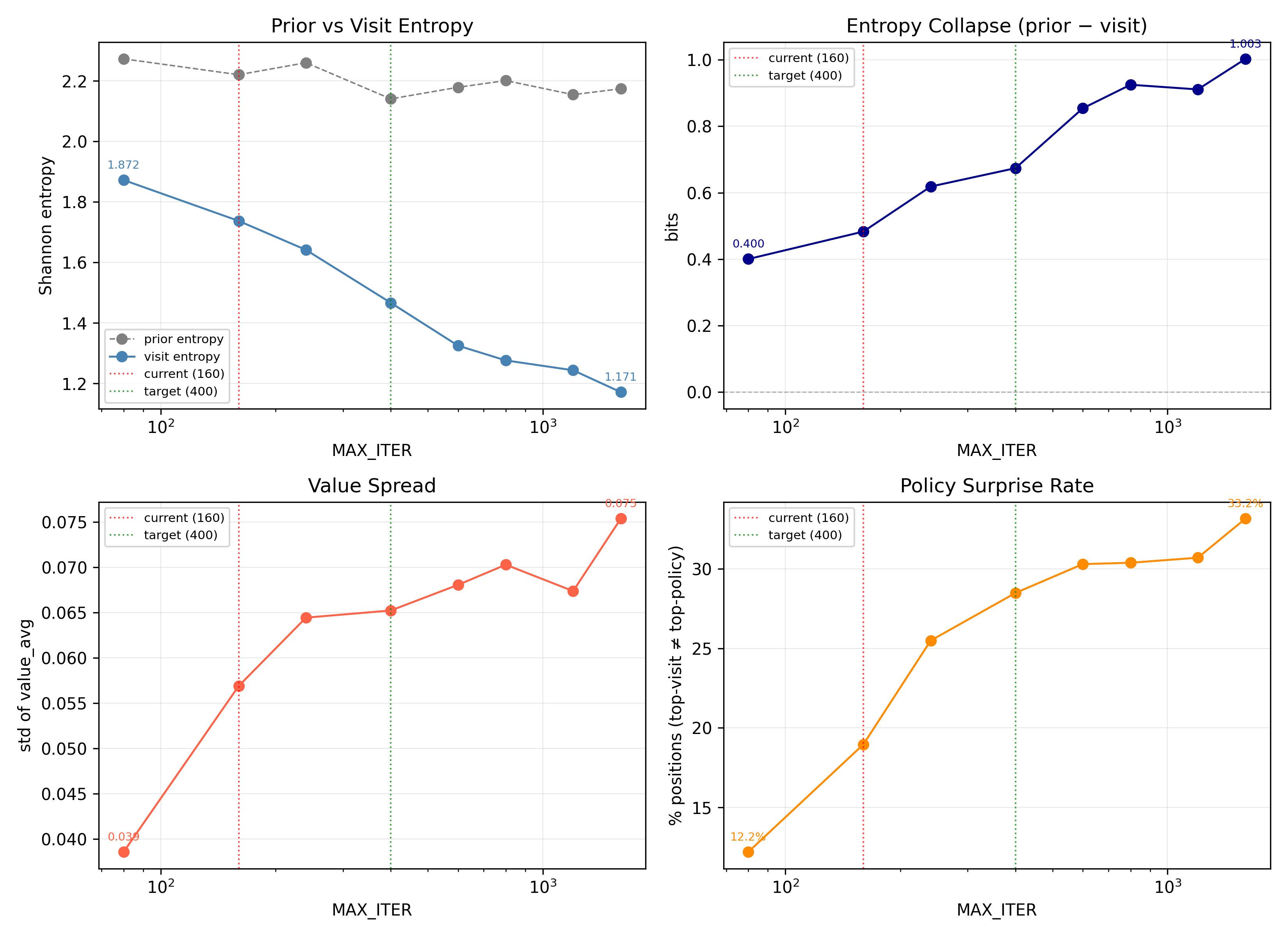
At MAX_ITER=160, entropy collapse is 0.48 bits and policy surprise is 19.0%. The search is doing work, but is still mostly following the prior.
By MAX_ITER=400, entropy collapse reaches 0.67 bits and policy surprise reaches 28.5%. The search has a stronger influence over the final distribution, and continues to influence the distribution more and more as search increases. I settled with MAX_ITER=400 as a good balance between compute and search quality.
6. Making changes
Given these results, I changed the following three parameters:
DIRICHLET_ALPHA:0.05→0.1use_forced_playouts_and_policy_target_pruning:True→Falsemax_iter:160→400
And the result?
Training was still stagnant. The model showed early improvements in APP (attack per piece) and DSPP (downstack pieces per piece) before plateauing, then performed poorly during gating checks against previous checkpoints. The hyperparameters weren't the root cause — the local minimum runs deeper than that.
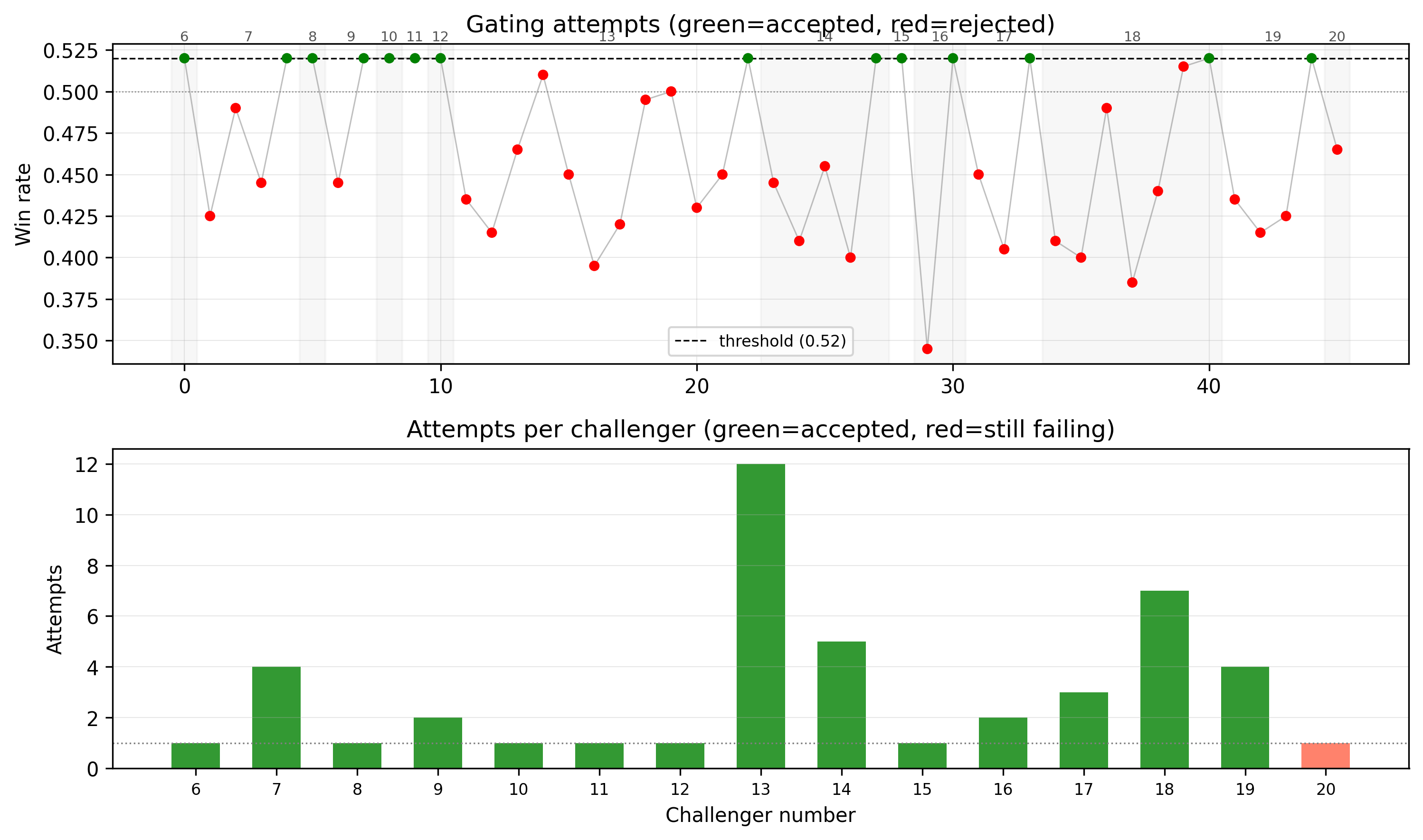
Each dot is a gating attempt — a match series against the previous accepted checkpoint, with a 52% win rate required for promotion. Green dots were accepted; red were rejected. Most challengers are failing to meet the threshold, showing that improvement is noisy and slow.
Chapter 2. Model Architecture
This entire algorithmic process takes place on my macbook. I've been playing self-play games one at a time, and to maximize inference speed, I've been using Keras with TFLite as it works well with Macbook CPUs. Additionally, my limited compute means that I have to keep my models relatively small. This chapter will explore various model architectures, and having to navigate running an entire reinforcement pipeline on my macbook!